Vulnerability Assessment e Penetration Test (VAPT): Analisi delle Vulnerabilità per Web, API, WordPress, Server e Cloud
Un Vulnerability Assessment professionale non è una lista di alert e non è una scansione fatta per riempire un PDF. È una risposta concreta a una domanda semplice: se qualcuno prova ad attaccare oggi il tuo sito, la tua API o la tua infrastruttura, dove passa, cosa può ottenere e quanto ti costa?
Il nostro approccio a Vulnerability Assessment e Penetration Test (VAPT) è orientato al rischio reale, alla remediation e alla decisione. Individuiamo vulnerabilità, misconfigurazioni, esposizioni e debolezze operative, le ordiniamo per priorità e impatto sul business, validiamo i finding più importanti e trasformiamo tutto in un piano di azione chiaro per Dev, IT, DevOps e management.
Quando serve, il Penetration Test va oltre l’identificazione e verifica la sfruttabilità in modo controllato. In questo modo non hai solo teoria o punteggi, ma evidenze tecniche utili a capire cosa correggere prima e perché.
Obiettivo finale: ridurre la superficie d’attacco, prevenire incidenti, rispondere a richieste enterprise e audit con documentazione seria, e accelerare la remediation con finding realmente utilizzabili.
- VAPT per Web, API, WordPress, Server e Cloud con scope chiaro e regole d’ingaggio definite
- Validazione mirata dei finding per ridurre falsi positivi e rumore operativo
- Report tecnico + executive con evidenze, priorità e remediation plan operativo
- Supporto alla remediation e re-test (opzionale) per confermare la chiusura
- Approccio Black Box, Grey Box o White Box in base a obiettivi, criticità e maturità
Indice della guida
- Cos’è un Vulnerability Assessment
- Perché una scansione automatica non basta
- Differenza tra Vulnerability Assessment, Penetration Test e VAPT
- Cosa ottieni: deliverable, report e risultati concreti
- Per chi è consigliato il servizio
- Quando fare un VA/PT e con quale frequenza
- Metodo di lavoro: come si svolge un assessment serio
- Definizione dello scope e regole d’ingaggio
- Cosa analizziamo: Web, API, WordPress, Server, Cloud
- Use case: e-commerce, SaaS, portali, WordPress, API mobile
- Come riduciamo falsi positivi e rumore
- Come definiamo severità e priorità di fix
- Esempi di vulnerabilità frequenti e impatto reale
- Remediation: quick win e interventi strutturali
- Cosa contiene il report (con demo PDF)
- Scansione gratuita: cosa ottieni e limiti
- Quando serve anche un Penetration Test
- Checklist di preparazione
- Tempi e costi: da cosa dipendono
- Errori comuni che rallentano remediation e sicurezza
- FAQ
- Richiedi un assessment completo
Cos’è un Vulnerability Assessment
Il Vulnerability Assessment (valutazione delle vulnerabilità) è un’attività tecnica che serve a identificare debolezze di sicurezza su sistemi, applicazioni e infrastrutture. In pratica significa: mappare ciò che è esposto, analizzare vulnerabilità note e misconfigurazioni, verificare il contesto, dare una priorità, e trasformare il risultato in un piano di correzione concreto.
Un assessment fatto bene non punta a trovare il maggior numero possibile di segnalazioni. Punta a trovare ciò che conta davvero, spiegare l’impatto e rendere la correzione semplice da eseguire e da verificare.
I 3 risultati che deve produrre un VA professionale
- Visibilità: sapere cosa è realmente esposto e raggiungibile dall’esterno o internamente.
- Priorità: capire cosa correggere prima in base a rischio reale, non solo a un punteggio.
- Azione: avere una remediation chiara, con indicazioni tecniche e passaggi di verifica.
Se il servizio non produce questi tre risultati, molto probabilmente hai ricevuto solo una scansione con tanto rumore e poco valore operativo.

Perché una scansione automatica non basta
Le scansioni automatiche sono utili e in molti casi vanno fatte. Il problema nasce quando vengono confuse con un Vulnerability Assessment completo. Una scansione può trovare segnali rapidi e aiutare a partire, ma non capisce da sola il contesto applicativo, la logica di business, i ruoli utente, il rischio reale e l’impatto sul tuo processo operativo.
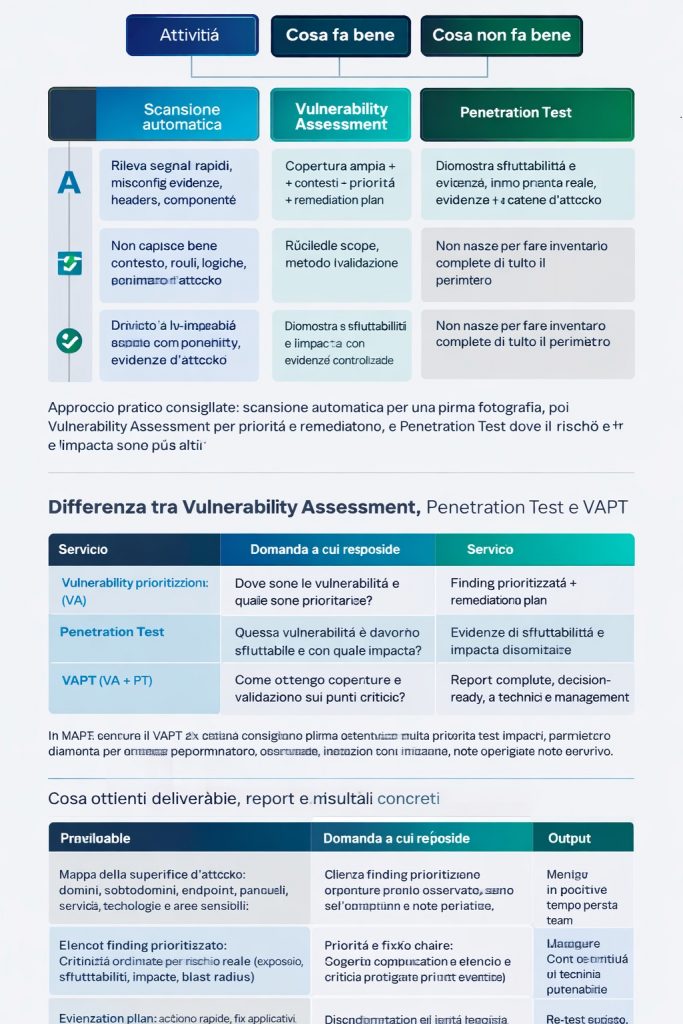
| Attività | Cosa fa bene | Cosa non fa bene |
|---|---|---|
| Scansione automatica | Rileva segnali rapidi, misconfig evidenti, headers, componenti obsoleti | Non capisce bene contesto, ruoli, logiche, impatto reale, catene d’attacco |
| Vulnerability Assessment | Copertura ampia + contesto + priorità + remediation plan | Richiede scope, metodo e validazione |
| Penetration Test | Dimostra sfruttabilità e impatto con evidenze controllate | Non nasce per fare inventario completo di tutto il perimetro |
Approccio pratico consigliato: scansione automatica per una prima fotografia, poi Vulnerability Assessment per priorità e remediation, e Penetration Test dove il rischio e l’impatto sono più alti.
Differenza tra Vulnerability Assessment, Penetration Test e VAPT
Le tre attività non sono alternative in senso assoluto. Rispondono a domande diverse e si completano a vicenda.
| Servizio | Domanda a cui risponde | Output |
|---|---|---|
| Vulnerability Assessment (VA) | Dove sono le vulnerabilità e quali sono prioritarie? | Finding prioritizzati + remediation plan |
| Penetration Test (PT) | Questa vulnerabilità è davvero sfruttabile e con quale impatto? | Evidenze di sfruttabilità e impatto dimostrato |
| VAPT (VA + PT) | Come ottengo copertura e validazione sui punti critici? | Report completo, decision-ready, utile a tecnici e management |
In molti scenari il VAPT è la soluzione migliore: prima ottieni visibilità e priorità su tutto il perimetro rilevante, poi validi in profondità ciò che può generare un incidente serio.
Cosa ottieni: deliverable, report e risultati concreti
Il valore del servizio si vede nei deliverable. Un buon assessment non produce solo un elenco di problemi, ma un set di output utilizzabili subito dal team.
Deliverable principali
- Mappa della superficie d’attacco: domini, sottodomini, endpoint, pannelli, servizi, tecnologie e aree sensibili.
- Elenco finding prioritizzato: criticità ordinate per rischio reale (esposizione, sfruttabilità, impatto, blast radius).
- Evidenze tecniche: endpoint, parametri, comportamento osservato, condizioni di riproduzione, note operative.
- Remediation plan: azioni rapide, fix applicativi, hardening infrastrutturale, note di verifica.
- Executive summary: sintesi leggibile per management, audit, procurement, clienti enterprise.
- Re-test (opzionale): verifica tecnica post-fix con conferma di chiusura dei finding.
Risultati concreti che deve generare un buon VAPT
- Riduzione dei tempi di remediation
- Meno falsi positivi e meno tempo perso dal team
- Priorità di fix più chiare
- Migliore comunicazione tra tecnici e management
- Maggiore controllo del rischio su asset esposti
- Documentazione utile per audit e richieste enterprise
Per chi è consigliato il servizio
Un servizio di Vulnerability Assessment e Penetration Test è utile per qualsiasi realtà con asset online, ma diventa particolarmente importante in questi casi:
- E-commerce con pagamenti, account utenti, coupon, ordini, area admin
- Portali clienti con documenti, fatture, ticket, dati riservati
- SaaS / piattaforme web con ruoli, multi-tenant, API e dashboard
- WordPress aziendali con plugin, temi e integrazioni terze parti
- API REST / GraphQL usate da app mobile, partner o sistemi interni
- Infrastrutture cloud con storage, IAM, CI/CD, container e segreti
- Aziende che devono rispondere a audit, vendor assessment, procurement o clienti enterprise
È particolarmente consigliato prima di go-live, dopo migrazioni, dopo modifiche architetturali, o quando il team vuole passare da una sicurezza reattiva a una sicurezza più gestita e misurabile.
Quando fare un VA/PT e con quale frequenza
Regola pratica: ogni volta che cambia il rischio, rifai la misura. Non serve aspettare un incidente o un cliente che te lo chiede.
- Dopo rilasci importanti (nuove feature, nuovi endpoint, nuove API)
- Dopo migrazioni (hosting, cloud, reverse proxy, WAF/CDN, database)
- Dopo installazione di plugin, moduli o componenti terzi
- Dopo cambi nei ruoli e nelle autorizzazioni applicative
- Dopo sospetti di compromissione o anomalie operative
- In modo periodico sugli asset critici, soprattutto se cambiano spesso
Per ambienti con rilasci frequenti, il modello migliore è: scansioni regolari + assessment mirati + re-test post-fix. Questo aiuta a ridurre il rischio senza bloccare delivery e operatività.
Metodo di lavoro: come si svolge un assessment serio
Un Vulnerability Assessment efficace non è un click. È un processo strutturato che combina discovery, analisi, validazione e prioritizzazione. Il flusso tipico può variare in base allo scope, ma segue una logica chiara.
- Pre-engagement e scoping: definizione di asset, ambienti, obiettivi, vincoli, modalità di test, contatti e finestre orarie.
- Asset discovery: mappatura di domini, sottodomini, endpoint, pannelli, tecnologie, servizi e superfici esposte.
- Attack surface mapping: identificazione dei punti di ingresso reali (login, form, upload, API, callback, admin, integrazioni).
- Analisi di vulnerabilità e misconfigurazioni: rilevazione e correlazione di segnali e finding.
- Validazione mirata: conferma tecnica dei finding più rilevanti per ridurre falsi positivi e capire impatto.
- Prioritizzazione: ranking per rischio reale e urgenza operativa.
- Report e remediation plan: output tecnico + executive con azioni suggerite.
- Re-test (opzionale): verifica di chiusura e conferma post-remediation.
Approcci possibili: Black Box, Grey Box, White Box
- Black Box: simula un attaccante esterno senza informazioni iniziali.
- Grey Box: usa credenziali o contesto limitato, ottimo equilibrio tra copertura e realismo.
- White Box: massima profondità, utile per applicazioni complesse, logiche di business e analisi avanzate.
In molti casi il Grey Box è il miglior compromesso per qualità dei finding e tempi, specialmente su aree autenticata, API e ruoli.
Definizione dello scope e regole d’ingaggio
Molti progetti di sicurezza falliscono non per mancanza di tecnica, ma per scope confuso. Uno scope ben fatto migliora qualità del risultato, tempi e costo.
Cosa definiamo nello scope
- Asset inclusi (domini, sottodomini, ambienti, API, IP, pannelli, servizi)
- Asset esclusi (per evitare impatti o conflitti operativi)
- Ambiente di test (production, staging, pre-prod)
- Finestra oraria e limiti di carico
- Contatti tecnici e escalation in caso di anomalie
- Approccio (Black Box, Grey Box, White Box)
- Eventuali credenziali di test e ruoli
- Vincoli su test distruttivi o ad alto impatto
Uno scope chiaro riduce rischi operativi, migliora la copertura utile e rende il report più credibile e più facile da usare per il team.
Cosa analizziamo: Web, API, WordPress, Server, Cloud
In base al tuo caso, l’analisi può includere uno o più ambiti. Sotto trovi una panoramica concreta di cosa verifichiamo in un servizio di analisi delle vulnerabilità e penetration test.
Web Application Security
- Attack surface: endpoint esposti, pagine sensibili, aree admin, endpoint legacy
- Authentication: brute force, enumeration, reset password, recovery flow, policy password
- Session management: cookie, timeout, logout, fixation, invalidazione sessioni
- Access control: ruoli, permessi, escalation, IDOR/Broken Access Control
- Input validation: XSS, SQLi, injection, traversal, template injection
- Upload security: validazione file, MIME, estensioni, permessi, storage
- Headers: CSP, HSTS, clickjacking, policy di sicurezza client-side
- Misconfig: debug, errori verbosi, directory listing, componenti obsoleti
API Security (REST / GraphQL)
- Token e auth: JWT/OAuth, scadenza, revoca, scope, audience
- Autorizzazioni: BOLA/IDOR, BFLA, multi-tenant access control
- Data exposure: campi sensibili, errori verbosi, leakage in response
- Rate limiting: brute force, abuse, enumeration, scraping
- CORS: policy troppo permissive, origini wildcard, credenziali
- Payload validation: injection su parametri JSON, mass assignment
- GraphQL: introspection, query complexity, depth, leakage
- Business logic: bypass workflow, controlli mancanti lato server
WordPress Security / CMS
- Plugin e temi: vulnerabilità note, versioni obsolete, manutenzione
- Hardening admin: brute force, enumeration utenti, MFA dove possibile
- Endpoint sensibili: admin, API, xmlrpc, aree legacy
- File esposti: backup, log, archivi, file temporanei, configurazioni
- Ruoli e capability: permessi impropri o troppo ampi
- Terze parti: script, tag, pixel, supply chain lato client
- Misconfig cache/CDN/WAF: bypass o esposizione aree riservate
Server, Rete e Cloud Security
- Servizi esposti: porte, pannelli, servizi non necessari, default
- TLS/SSL: protocolli, cipher, certificati, configurazione trasporto
- Segreti e credenziali: esposizione, gestione, rotazione
- IAM: policy troppo ampie, least privilege, chiavi persistenti
- Storage: bucket pubblici, listing, accesso a oggetti sensibili
- Container/CI-CD: permessi, immagini, pipeline, gestione segreti
- Logging e monitoraggio: visibilità minima, audit trail, segnali utili
- Hardening: riduzione attack surface e baseline di sicurezza
Se il perimetro è ampio, si lavora per priorità: prima gli asset più esposti e critici, poi hardening e approfondimenti sul resto. Questo approccio porta risultati concreti più rapidamente.
Use case: dove il VAPT fa davvero la differenza
Qui sotto trovi scenari molto comuni in cui un Vulnerability Assessment e Penetration Test produce valore immediato.
1) E-commerce con pagamenti e account utenti
Priorità tipiche: aree admin, gestione ordini, coupon, upload, reset password, API di checkout, esposizione dati cliente. In questo contesto una debolezza di access control o un plugin non aggiornato può generare danni economici e reputazionali molto rapidi.
2) SaaS / piattaforma con ruoli e tenant
Priorità tipiche: autorizzazioni multi-tenant, BOLA/IDOR, escalation di privilegi, leakage tra account, API interne esposte. Qui il rischio non è solo tecnico ma contrattuale, perché l’isolamento dei dati tra clienti è centrale.
3) WordPress aziendale con plugin multipli
Priorità tipiche: plugin e temi vulnerabili, login hardening, file di backup accessibili, misconfig di caching/CDN, endpoint sensibili, integrazioni marketing con script terzi. Spesso i problemi sono risolvibili rapidamente se vengono visti in tempo.
4) API per app mobile o integrazione partner
Priorità tipiche: token, autorizzazioni, rate limit, BOLA, data exposure, error handling, CORS. Le API vengono spesso esposte a volumi e automazione elevata, quindi anche una debolezza media può diventare critica in produzione.
5) Migrazione cloud / redesign infrastrutturale
Priorità tipiche: IAM, storage, segreti, servizi pubblici non necessari, policy troppo ampie, logging insufficiente. Il rischio cresce quando l’infrastruttura cambia velocemente e la configurazione non viene validata con metodo.
Come riduciamo falsi positivi e rumore
Uno dei problemi più costosi nelle attività di sicurezza è il rumore. Un assessment serio deve ridurre il tempo perso dal team, non aumentarlo.
- Validazione tecnica dei finding critici: verifichiamo ripetibilità, condizioni e comportamento coerente.
- Contesto applicativo: endpoint pubblico o autenticato? ruolo richiesto? impatto su dati e funzioni?
- Deduplicazione: raggruppiamo segnali simili in finding utili da correggere.
- Priorità orientata al rischio: focus su compromissione, data exposure, takeover, abuso API.
- Evidenze chiare: dove utile inseriamo request/response, endpoint, passaggi di verifica, note di riproduzione.
Questo approccio consente al team di lavorare su un backlog di sicurezza più pulito, più credibile e più veloce da smaltire.
Come definiamo severità e priorità di fix
La severità tecnica da sola non basta. Per decidere cosa correggere prima valutiamo il rischio reale, cioè la combinazione tra esposizione, sfruttabilità, impatto, probabilità e blast radius.
| Fattore | Cosa valutiamo | Esempio pratico |
|---|---|---|
| Esposizione | Internet-facing, dietro login/VPN, visibilità del punto di ingresso | Endpoint admin pubblico aumenta urgenza |
| Sfruttabilità | Prerequisiti, ruolo richiesto, facilità dell’attacco | Exploit in una richiesta è più urgente |
| Impatto | Dati, account, pagamenti, continuità operativa | IDOR su documenti clienti è alto impatto |
| Probabilità | Quanto è comune l’attacco e quanto è facile da individuare | Plugin WP noto aumenta probabilità |
| Blast radius | Numero di utenti/sistemi coinvolti se sfruttato | API multi-tenant con permessi deboli |
| Livello | Significato operativo | Azione consigliata |
|---|---|---|
| Critico | Compromissione o esposizione dati plausibile e immediata | Mitigazione rapida + fix definitivo + verifica |
| Alto | Impatto significativo con sfruttamento realistico | Fix prioritario nel prossimo ciclo di rilascio |
| Medio | Serve una condizione specifica o impatto limitato | Pianificare remediation e hardening |
| Basso | Best practice o impatto contenuto | Gestire in manutenzione programmata |
| Info | Osservazioni utili, postura, inventario | Documentare e usare per miglioramento continuo |
Risultato: meno discussioni inutili sul punteggio, più decisioni rapide e più fix chiusi.
Esempi di vulnerabilità frequenti e impatto reale
Questi sono esempi comuni su siti, e-commerce, portali e API. Non servono scenari hollywoodiani. Bastano errori comuni non intercettati in tempo.
- IDOR / BOLA: cambiando un ID si accede a risorse di altri utenti (ordini, documenti, profili).
- Broken Access Control: funzioni admin o di gestione raggiungibili con ruoli non autorizzati.
- Account takeover: brute force, reset password debole, sessioni non invalidate, MFA assente.
- XSS persistente: furto di sessione, azioni a nome utente, manipolazione contenuti.
- SQL Injection: lettura dati, bypass login, estrazione di informazioni sensibili.
- File upload pericoloso: upload di file eseguibili o malevoli per webshell/malware.
- SSRF: accesso a risorse interne o metadata service cloud tramite richieste server-side.
- Misconfig cloud/IAM: storage pubblico, policy troppo ampie, chiavi esposte, ruoli eccessivi.
- Backup e file sensibili esposti: dump, zip, log, .env, file temporanei, archivi legacy.
- Headers e cookie deboli: clickjacking, session hijacking, leakage e downgrade di sicurezza.
- Rate limiting assente: enumeration, brute force, abuso API, scraping aggressivo.
- Error handling verboso: stack trace, versioni, percorsi interni, leakage utile all’attaccante.
Il punto non è fare paura. Il punto è essere pratici: queste vulnerabilità sono tra le più comuni e spesso tra le più evitabili con una buona analisi e remediation rapida.
Remediation: quick win e interventi strutturali
Un report utile non si ferma a dire “c’è una vulnerabilità”. Deve dire cosa fare adesso, cosa pianificare e come verificare. Per questo separiamo spesso le azioni in categorie operative.
Quick win (alto impatto, tempi rapidi)
- Patch di componenti critici
- Chiusura endpoint/servizi esposti non necessari
- Hardening login e admin
- Rate limit su endpoint sensibili
- Security headers e cookie policy
- Rimozione file backup/log esposti
Fix applicativi (server-side e logica)
- Controlli di autorizzazione lato server
- Validazione input e output encoding
- Gestione sessione e token
- Gestione errori e logging sicuro
- Protezioni su upload e parsing
Interventi strutturali (riduzione rischio nel tempo)
- Riduzione attack surface
- Least privilege su IAM e ruoli applicativi
- Rotazione credenziali e segreti
- Miglioramento logging, monitoraggio e alerting
- Baseline di hardening su server e cloud
- Processo di re-test e verifica post-fix
Obiettivo finale: ridurre il rischio subito e migliorare la resilienza del sistema nel medio termine.
Cosa contiene il report (con demo PDF)
Il report deve essere fatto per lavorare, non per fare scena. Per questo è utile che sia leggibile sia da chi decide, sia da chi deve implementare la correzione.
Executive Summary (management, audit, procurement)
- Scope e asset analizzati
- Sintesi del rischio complessivo
- Top criticità e impatto potenziale sul business
- Priorità di intervento e ordine di fix consigliato
- Note su re-test e stato delle correzioni (se effettuato)
Sezione tecnica (IT, Dev, DevOps, Security)
- Finding dettagliati con classificazione e contesto
- Evidenze tecniche (endpoint, parametri, comportamento)
- Condizioni di sfruttamento / verifica dove applicabile
- Remediation plan con azioni pratiche
- Note di hardening e miglioramento postura
Apri un esempio di report
Vuoi vedere come appare un report completo con executive summary e dettagli tecnici? Apri il PDF demo:
Puoi anche incorporare il PDF nella pagina (opzionale):
Scansione gratuita: cosa ottieni e quali sono i limiti
La scansione gratuita è un ottimo punto di partenza per ottenere una prima fotografia del rischio, specialmente se vuoi capire rapidamente se ci sono esposizioni evidenti o configurazioni deboli.
- Avvio rapido: inserisci il dominio e lanci l’analisi
- Risultati immediati: segnali iniziali e raccomandazioni di base
- Prima priorità: capisci dove conviene guardare subito
Cosa può rilevare bene: headers, segnali di misconfigurazione, componenti esposti, errori verbosi, alcune esposizioni note. Cosa non sostituisce: contesto applicativo, logica di business, ruoli, autorizzazioni complesse, chaining, sfruttabilità reale e impatto operativo.
Nota importante: la scansione automatizzata è un inizio. Se devi prendere decisioni serie, pianificare remediation o rispondere a richieste enterprise, serve un assessment completo e, quando necessario, un Penetration Test.
Quando serve anche un Penetration Test
Il Penetration Test è particolarmente utile quando vuoi trasformare un sospetto o un finding in una prova tecnica controllata. Non sempre serve su tutto, ma su alcune aree è spesso decisivo.
- Login, ruoli, autorizzazioni, aree riservate
- Pagamenti, ordini, documenti, dati sensibili
- API usate da app mobile o partner
- Portali multi-tenant e SaaS
- Go-live o migrazioni recenti
- Richieste enterprise, audit, procurement, assicurazioni cyber
Strategia pratica ad alta efficacia: scansione gratuita, poi Vulnerability Assessment completo, poi Penetration Test mirato sui punti a maggiore impatto.
Checklist di preparazione (per accelerare il lavoro e migliorare i risultati)
Per ottenere un assessment più efficace, prepara quello che puoi. Se non hai tutto, si può comunque partire in Black Box.
- Lista domini, sottodomini, ambienti (prod, staging, pre-prod)
- Elenco API / documentazione base (se disponibile)
- Credenziali di test e ruoli (Grey Box), se previsti
- Vincoli orari o limiti di carico
- Contatto tecnico per chiarimenti e validazioni rapide
- Info su stack (CMS, framework, cloud provider, WAF/CDN)
- Eventuali allowlist IP o policy di blocco da coordinare
- Segnalazione di sistemi fragili o esclusi
Una preparazione minima fatta bene migliora copertura, tempi e qualità del report. Se non hai nulla di pronto, lo definiamo insieme nello scoping.
Tempi e costi: da cosa dipendono davvero
Tempi e costi di un Vulnerability Assessment / Penetration Test dipendono soprattutto dallo scope e dalla complessità, non dal semplice numero di pagine del sito.
| Fattore | Impatto su tempi/costi | Esempio |
|---|---|---|
| Numero di asset | Aumenta discovery, analisi e reportistica | Più domini, API, ambienti, pannelli |
| Profondità del test | Aumenta validazione e attività manuale | Grey Box / White Box più profondi |
| Funzioni critiche | Aumenta attenzione e verifica | Pagamenti, upload, ruoli, area admin |
| Complessità applicativa | Aumenta effort di comprensione e test | SaaS, multi-tenant, workflow complessi |
| Cloud / infra | Aumenta coverage tecnica e posture review | IAM, storage, servizi esposti, CI/CD |
| Re-test | Aggiunge ciclo di verifica post-fix | Conferma chiusura criticità |
Per fare bene e veloce, la cosa più importante è uno scope chiaro. Uno scope fatto bene fa risparmiare tempo, soldi e discussioni inutili durante remediation.
Errori comuni che rallentano remediation e sicurezza
Molti problemi non dipendono dalla mancanza di strumenti, ma da errori di processo. Ecco quelli più frequenti:
- Confondere scansione con assessment: si ricevono alert, ma non priorità utili.
- Scope troppo vago: tempo perso su asset secondari, buchi sugli asset critici.
- Zero contesto: finding corretti ma poco utili senza capire ruoli, dati, business.
- Fissarsi solo sul punteggio: si ignorano fattori come esposizione e blast radius.
- Nessun re-test: si crede di aver chiuso una vulnerabilità senza verifica.
- Report non action-oriented: il team perde tempo a interpretare invece che correggere.
- Assenza di owner interni: nessuno prende in carico remediation e timing.
Un buon VAPT riduce proprio questi attriti: meno rumore, più chiarezza, più chiusure reali.

FAQ: Vulnerability Assessment e Penetration Test (VAPT)
Il Vulnerability Assessment elimina le vulnerabilità?
No. Le identifica, le classifica e fornisce un remediation plan. Su richiesta possiamo supportare anche la correzione e il re-test.
Qual è la differenza tra scansione automatica e VAPT?
La scansione automatica offre una prima fotografia con segnali rapidi. Il VAPT aggiunge contesto, validazione, priorità reali, evidenze e remediation plan.
È adatto a WordPress?
Sì. WordPress è uno dei contesti dove un assessment ben fatto è spesso molto utile, soprattutto per plugin, temi, hardening admin, file esposti e misconfigurazioni.
Serve sempre anche un Penetration Test?
Non sempre. È consigliato quando hai login, ruoli, dati sensibili, pagamenti, API o scenari ad alto impatto e vuoi verificare la sfruttabilità reale in modo controllato.
Quanto spesso va fatto?
Dopo rilasci importanti, migrazioni, nuove integrazioni, nuovi plugin/moduli e periodicamente sugli asset critici.
C’è rischio di impattare l’operatività?
Il rischio si riduce con scope chiaro, regole d’ingaggio, finestre orarie, limiti di carico e validazione controllata. Se ci sono sistemi fragili, si definiscono limiti specifici.
Fate re-test dopo la correzione?
Sì, il re-test è opzionale e serve a confermare tecnicamente che i finding siano chiusi e che le correzioni siano efficaci.
Il report è utile anche per management o audit?
Sì. Un buon report include sia sezione tecnica sia executive summary, con priorità, impatto e piano di azione.
La scansione gratuita basta per clienti enterprise o audit?
In genere no. È utile come primo passo, ma per richieste enterprise e decisioni di remediation serve un assessment completo, spesso con validazione mirata e report strutturato.
Richiedi un Vulnerability Assessment completo
Vuoi un report completo con evidenze, priorità e remediation plan, senza rumore inutile? Contattaci e definiamo lo scope ideale per il tuo caso. Se emergono criticità, possiamo supportarti anche nella remediation e nel re-test.
Se preferisci partire subito, usa la scansione gratuita per ottenere una prima fotografia del rischio e poi decidere il passo successivo con dati concreti.
Link interni consigliati (SEO e conversione)
Per rafforzare la pagina lato SEO e UX, collega internamente questa guida ad altre pagine/servizi pertinenti (adatta gli URL al tuo sito):
- Contatti / richiesta preventivo
- Penetration Test WordPress (se esiste)
- API Security Testing (se esiste)
- Hardening WordPress (se esiste)
- Remediation vulnerabilità (se esiste)
- Articoli di cyber security correlati (se esiste)